tabby源码阅读
前言
看了南大的软件分析课程,还是很有意思的,顺便学了soot,终于是可以看明白tabby源码了。
soot教程见 https://fynch3r.github.io/soot%E7%9F%A5%E8%AF%86%E7%82%B9%E6%95%B4%E7%90%86/ ,总结的挺牛逼的。
tabby分析参考:
https://m0d9.me/2022/10/22/Tabby-%E5%B7%A5%E5%85%B7%E5%88%86%E6%9E%90/
https://tttang.com/archive/1696/#toc_11
本文只记录较为关键的部分。
类/方法信息搜集
和GadgetInspector一样,先搜集类和方法的信息。然后build调用图
ClassInfoScanner#run

先后调用了这些方法,一个一个看。
loadAndExtract
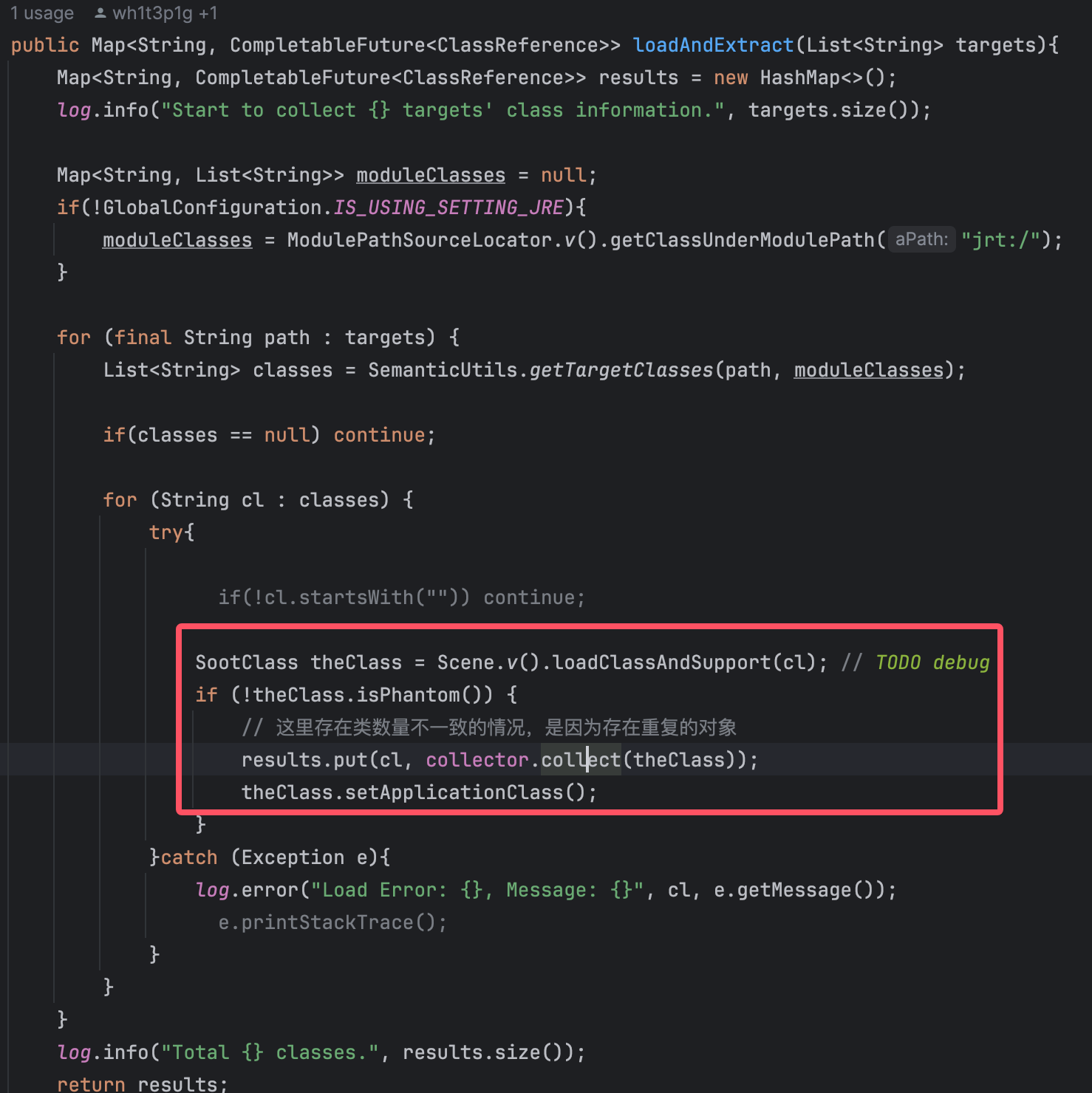
关键在于collector.collect, theClass是SootClass,这个是Soot的类。一个SootClass包含一个Java类所有相关的信息,例如这个类的类名、修饰符、父类、SootField、SootMethod链等。
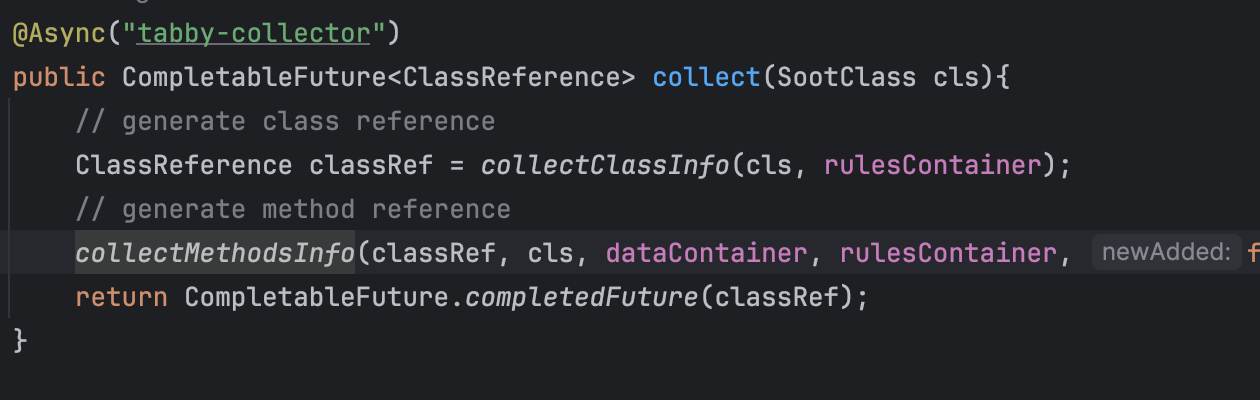
搜集了类和方法的信息,这里有两个作者自定义的数据结构,ClassReference和MethodReference,用于储存信息。
都是把SootClass和SootMethod提取出来,丢进xxRefence的newInstance方法构建。
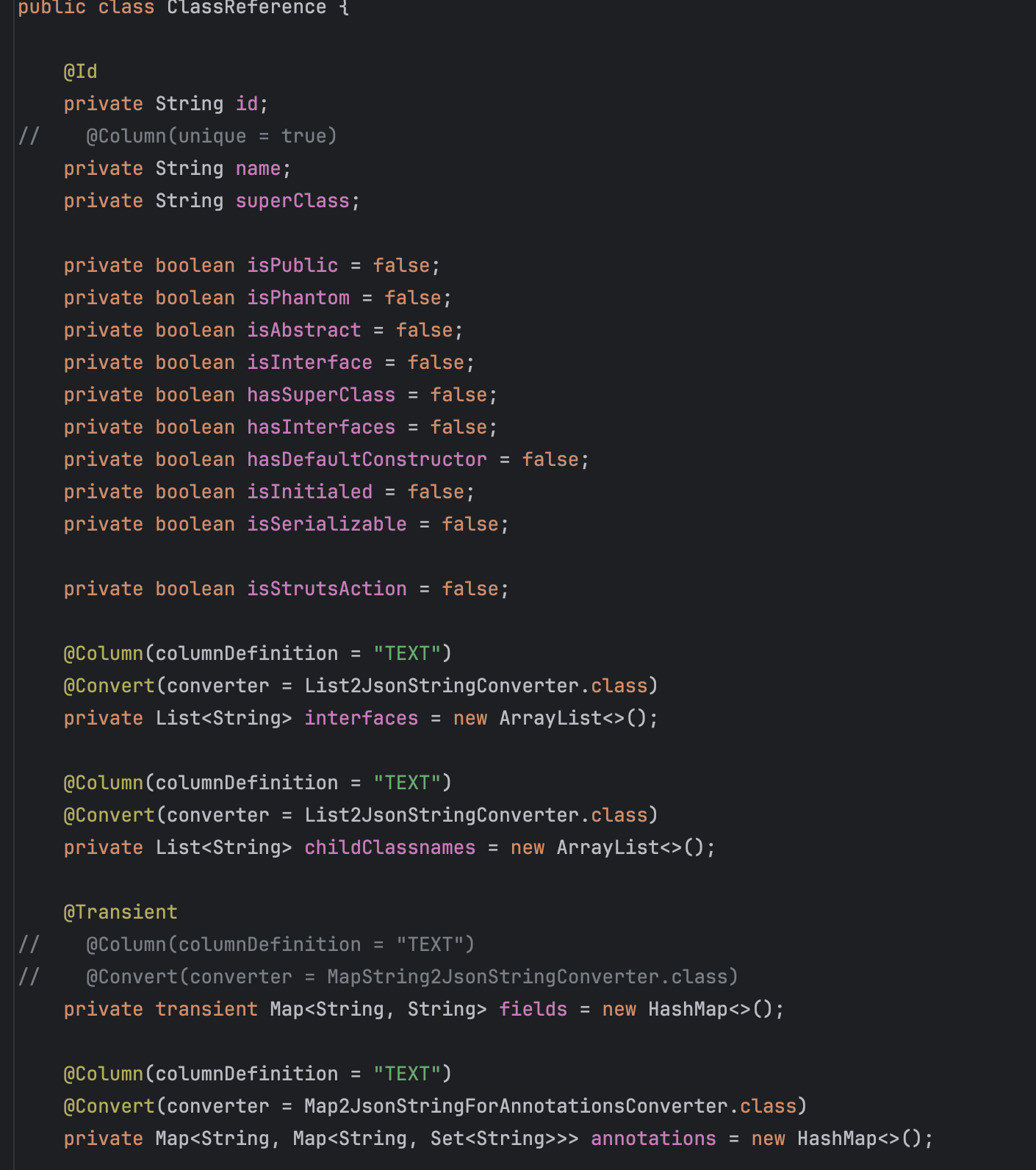
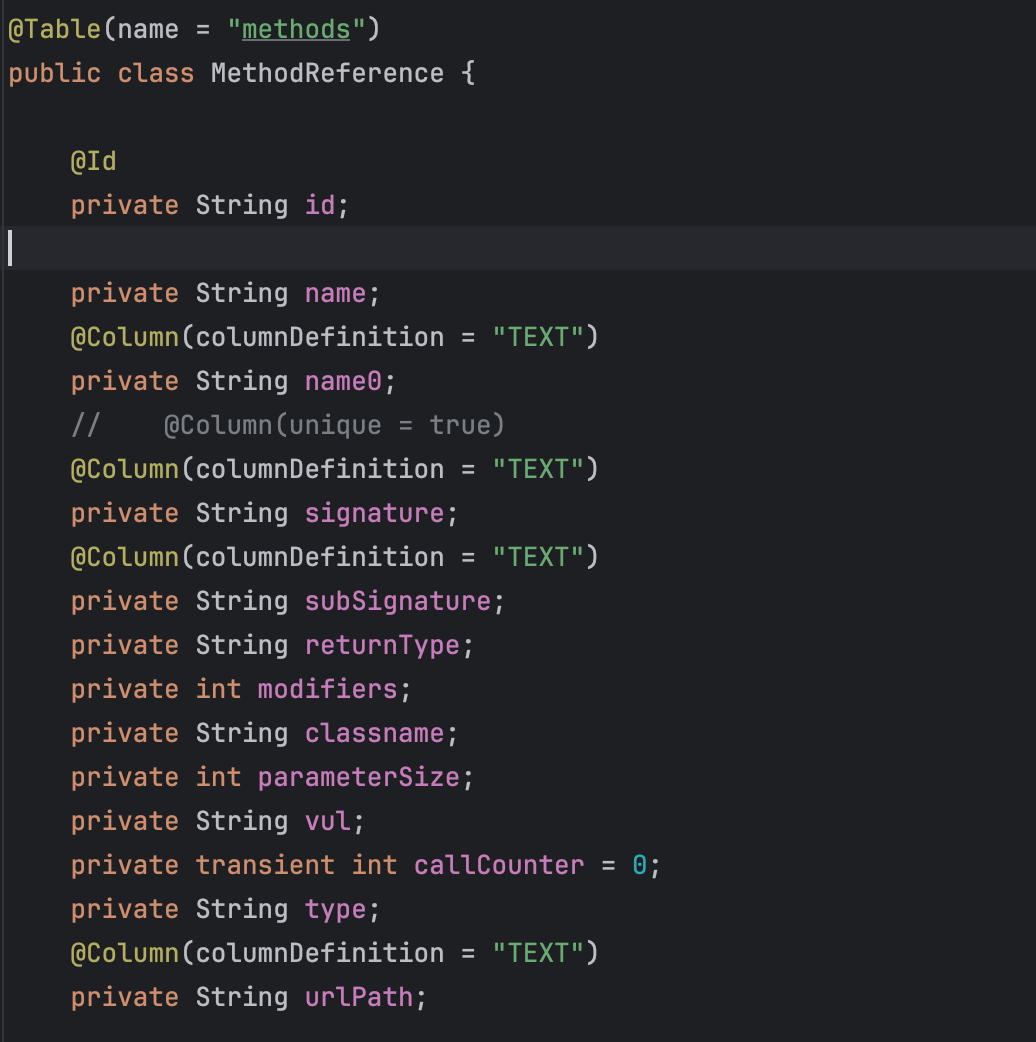
可以看到还用到了@Column注解,用于未来保存信息到数据库。
最后MethodReference信息丢进dataContainer里,classReference的信息Return回去。
DataContainer Field如下,存放了各种需要用到的信息:

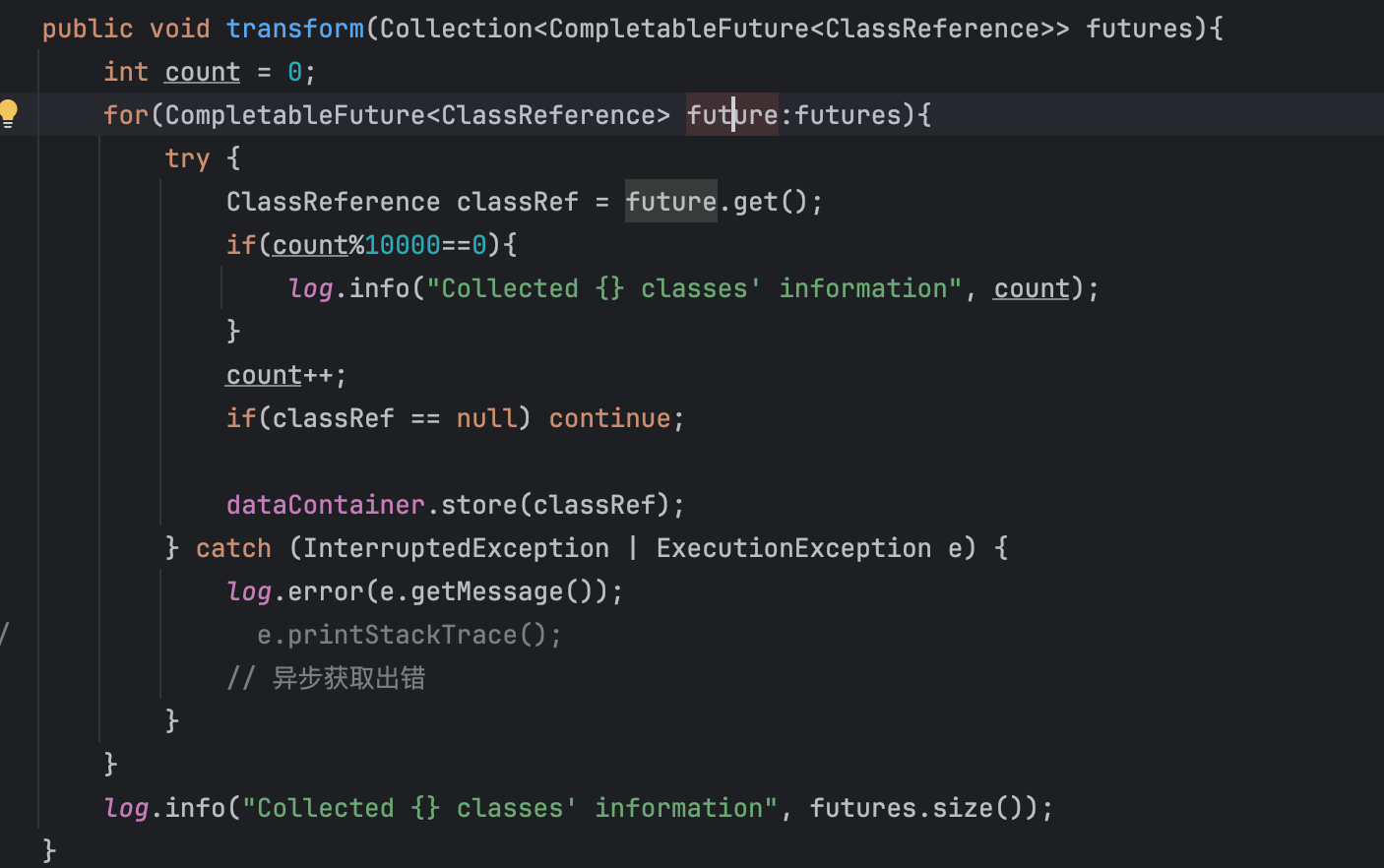
transform
主要就是把ClassRef信息丢进dataContainer里。
buildClassEdges
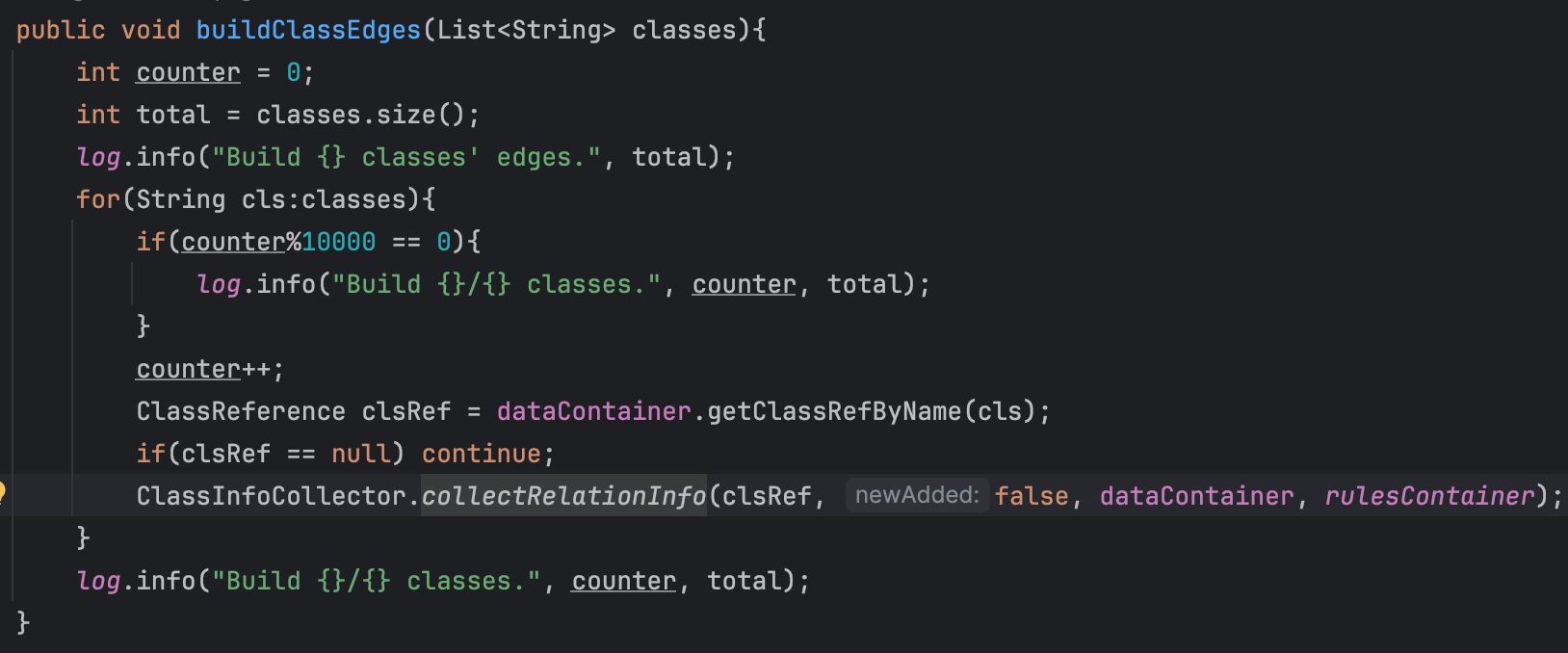
到collectionRelationInfo
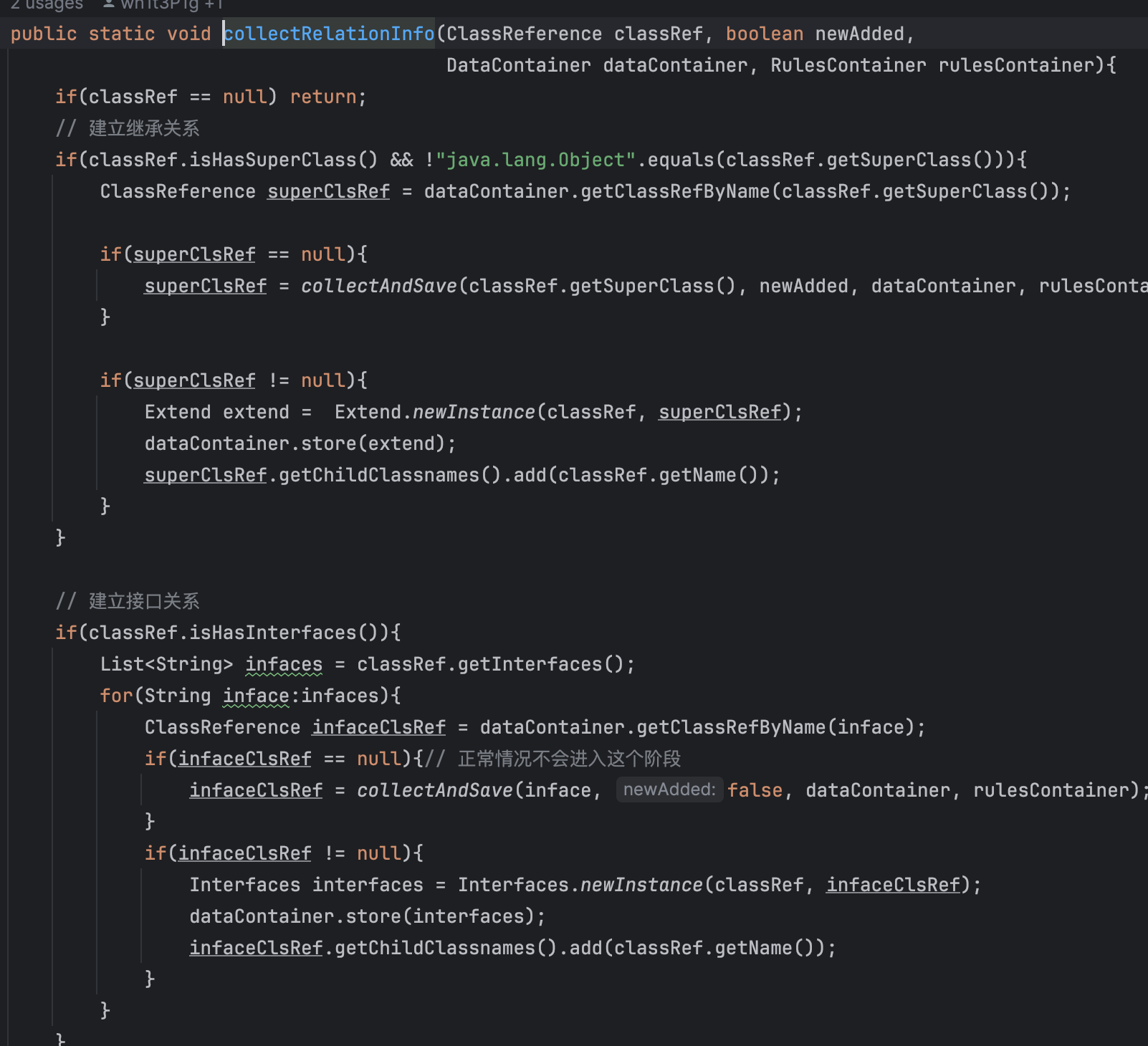
可以看到处理接口,类继承,函数别名的信息。
最后是save,作者用了springboot框架,对这些信息写了Repository和Service,方便和数据库交互。具体都在这里:
CallGraph构建
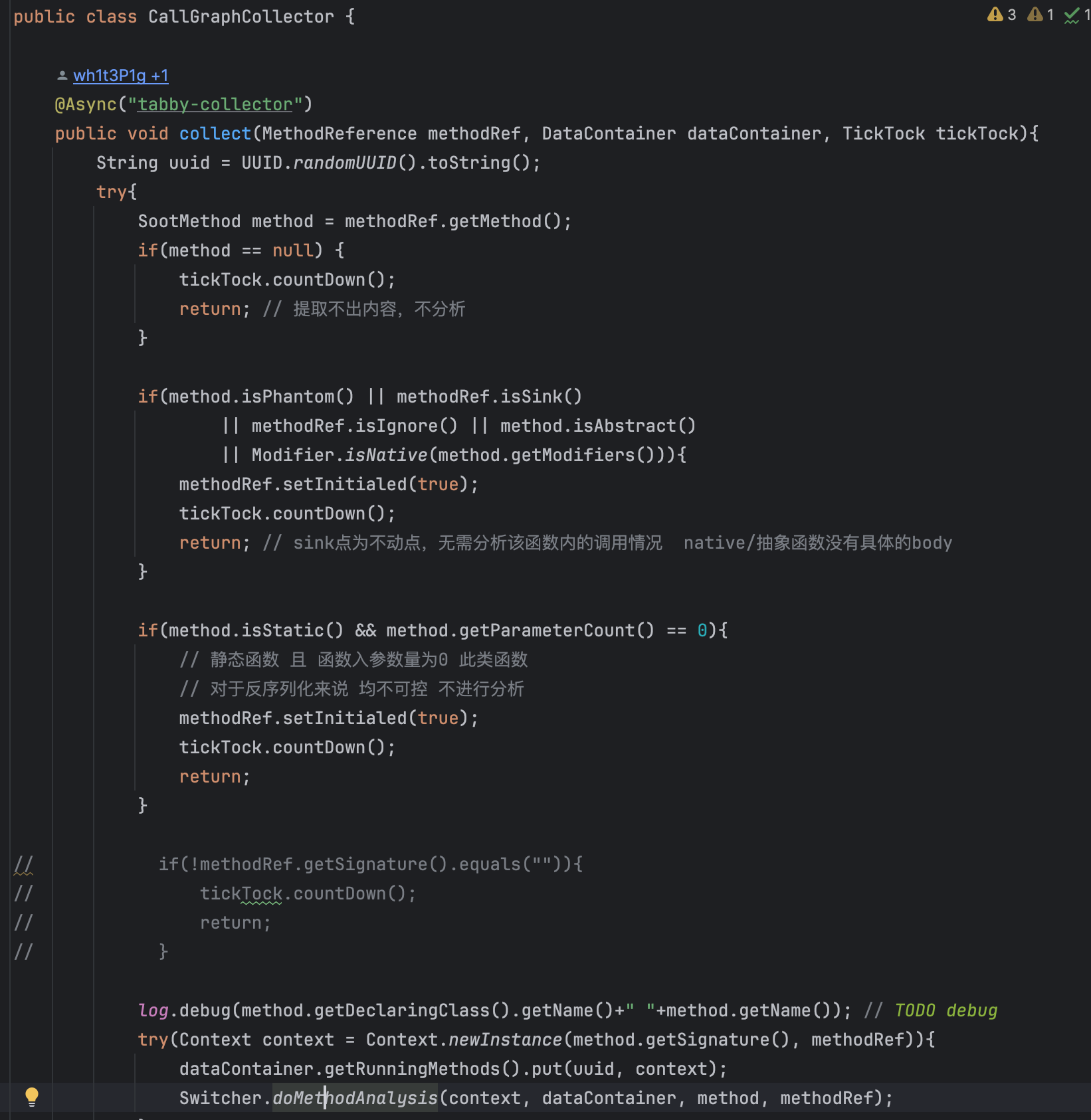
CallGraphCollector#collect
对于一些方法,Phantom方法,sink,忽略的,抽象方法和native方法,这些都没法分析。(sink不需要分析)直接跳过。
Phantom:

然后是无参的static method,没法控制,也直接跳了。
Switcher#doAnalysis
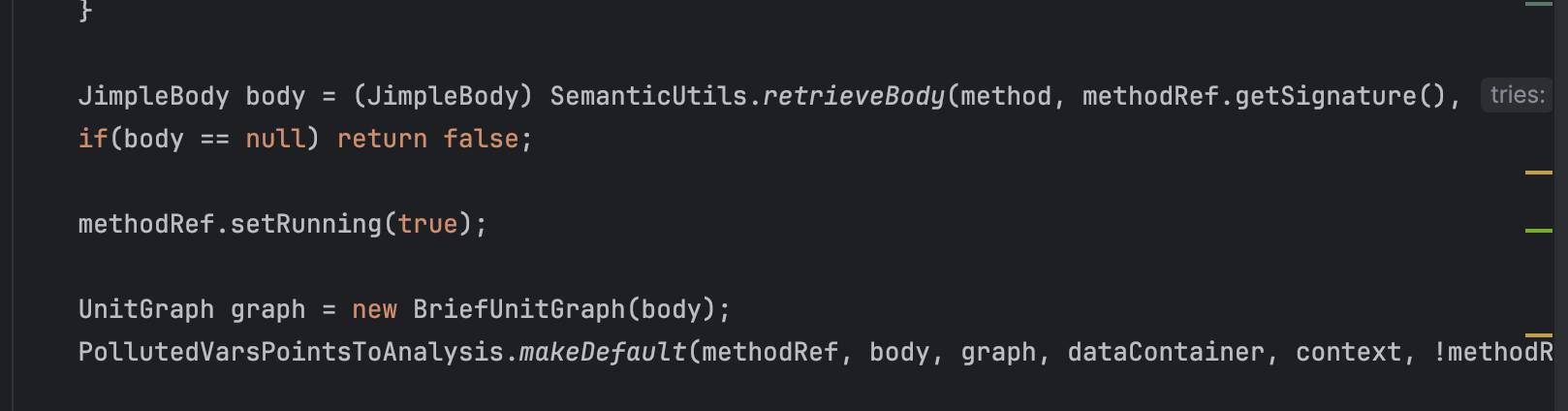
提取了method的body部分(Jimple码格式)
然后构建了BriefUnitGraph。
makeDefault里主要是new一个PollutedVarsPointsToAnalysis。这块是关键。
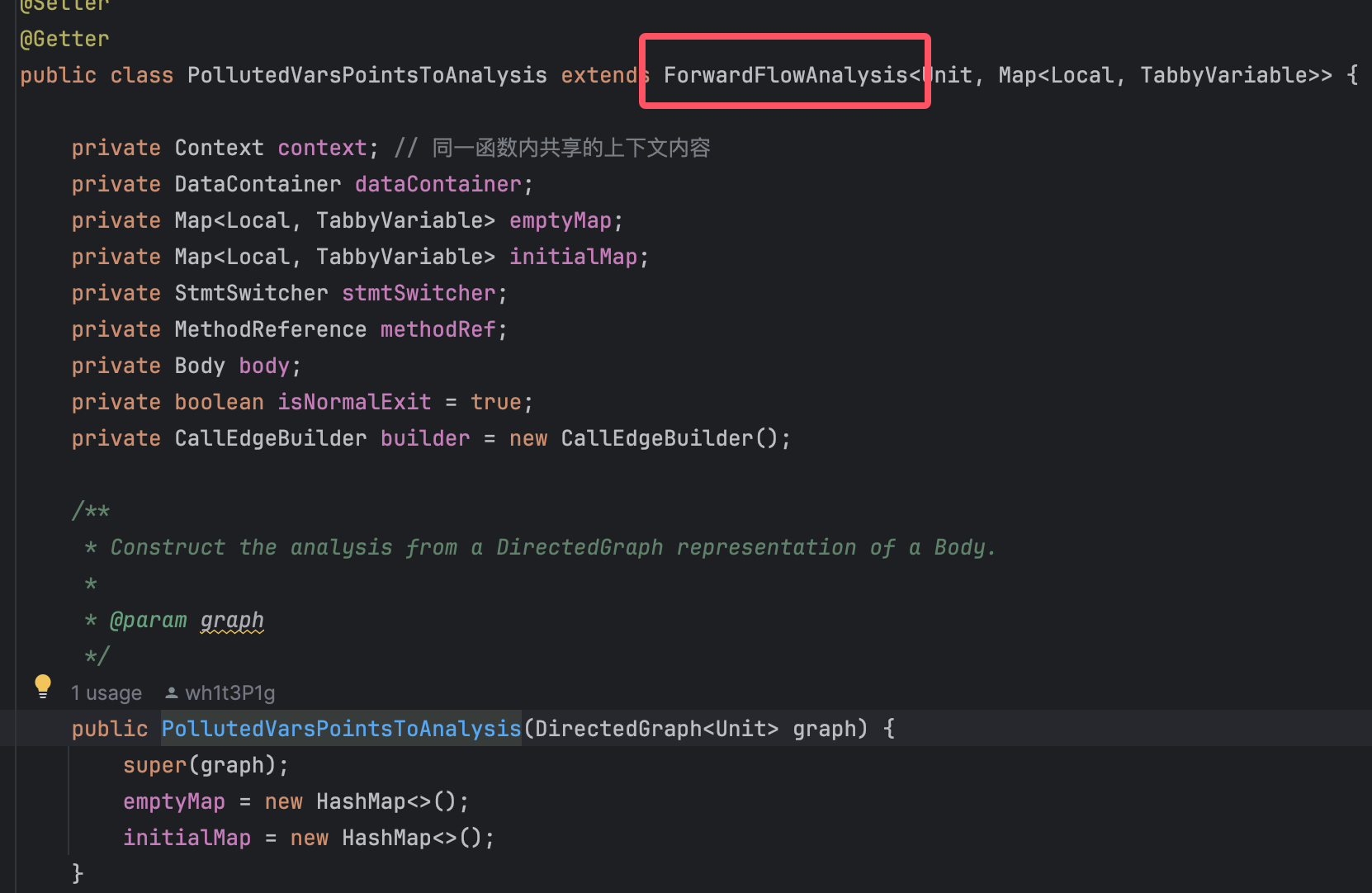
前向分析。
LiveVariablesAnalysis示例
先不看这个,有点复杂,先来看怎么用soot实现LiveVariablesAnalysis
https://github.com/PL-Ninja/MySootScript
先来看算法:
看起来挺复杂,其实就是不断的kill掉定义的variable,并上use过的variable,具体例子可以看这个:
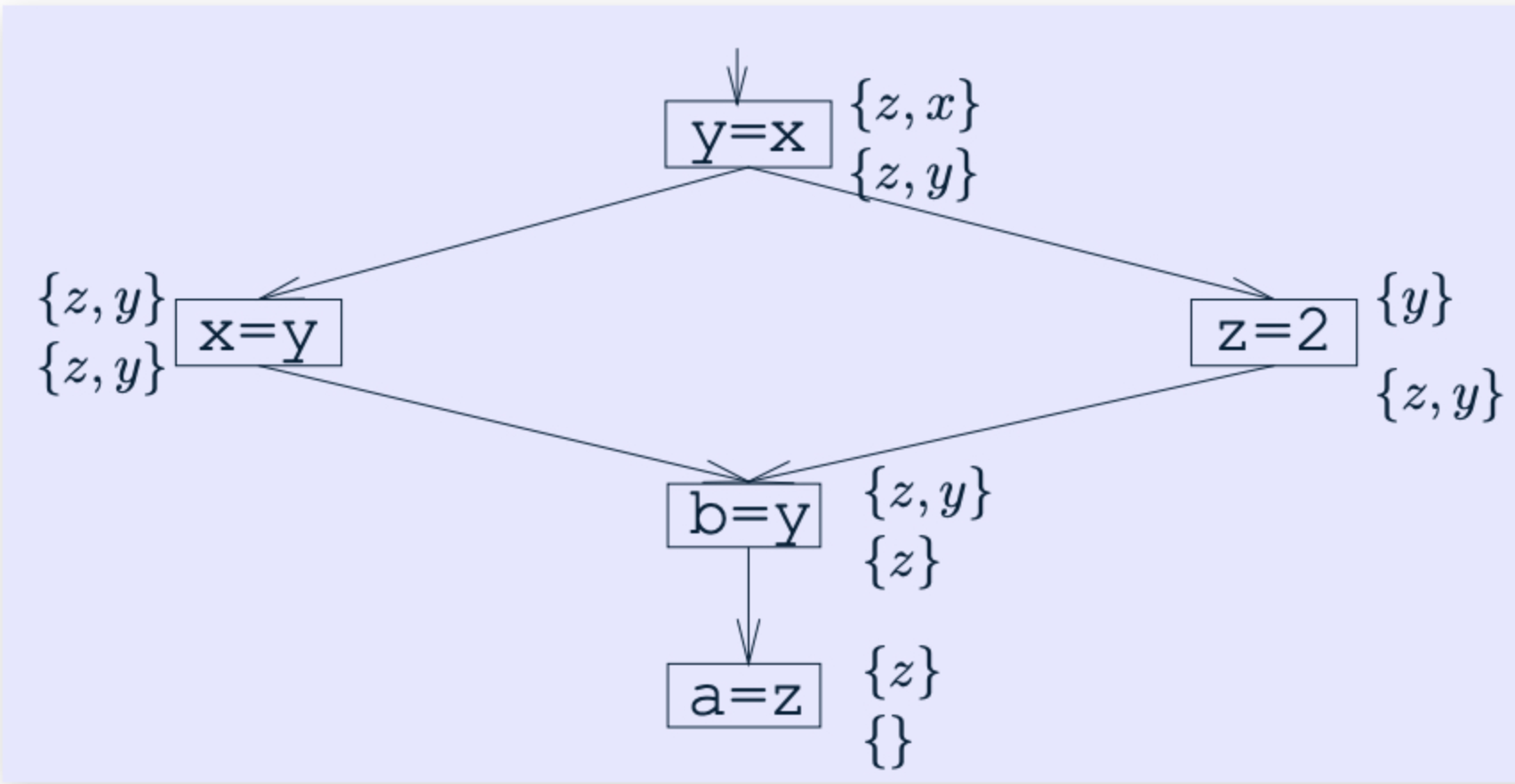
tabby那个是正向分析,这个LiveVariablesAnalysis的实现是反向的,从后往前看。
每个框旁边有两个集合,上面是IN set, 下面是OUT set
a=z, kill a, add z, 因为本来就没a,不用管它,所以IN = {z},然后直接把这个In set copy到b=y的out set
b=y, kill b, add y, 所以IN = {z, y}
然后是对于分支操作,做union,可以看到{z, y}和{y} merge成了{z, y}
后续的y=x也同理。最后得到z ,x 。
如何实现的呢?

先看SimpleLiveVariablesAnalysis.java
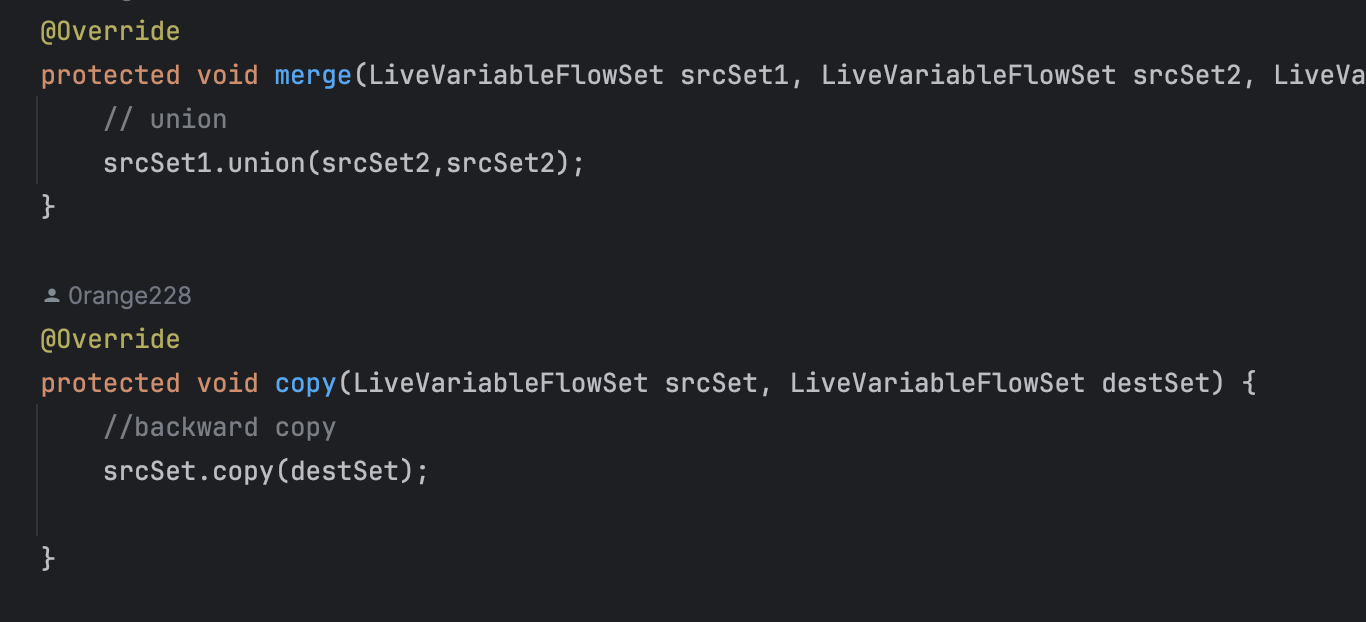
merge和copy操作没啥多说的,直接调soot的api即可。
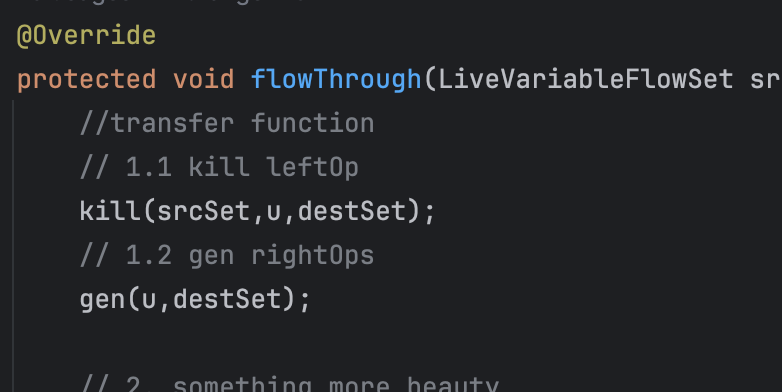
flowThrough方法是实现数据流分析的函数。
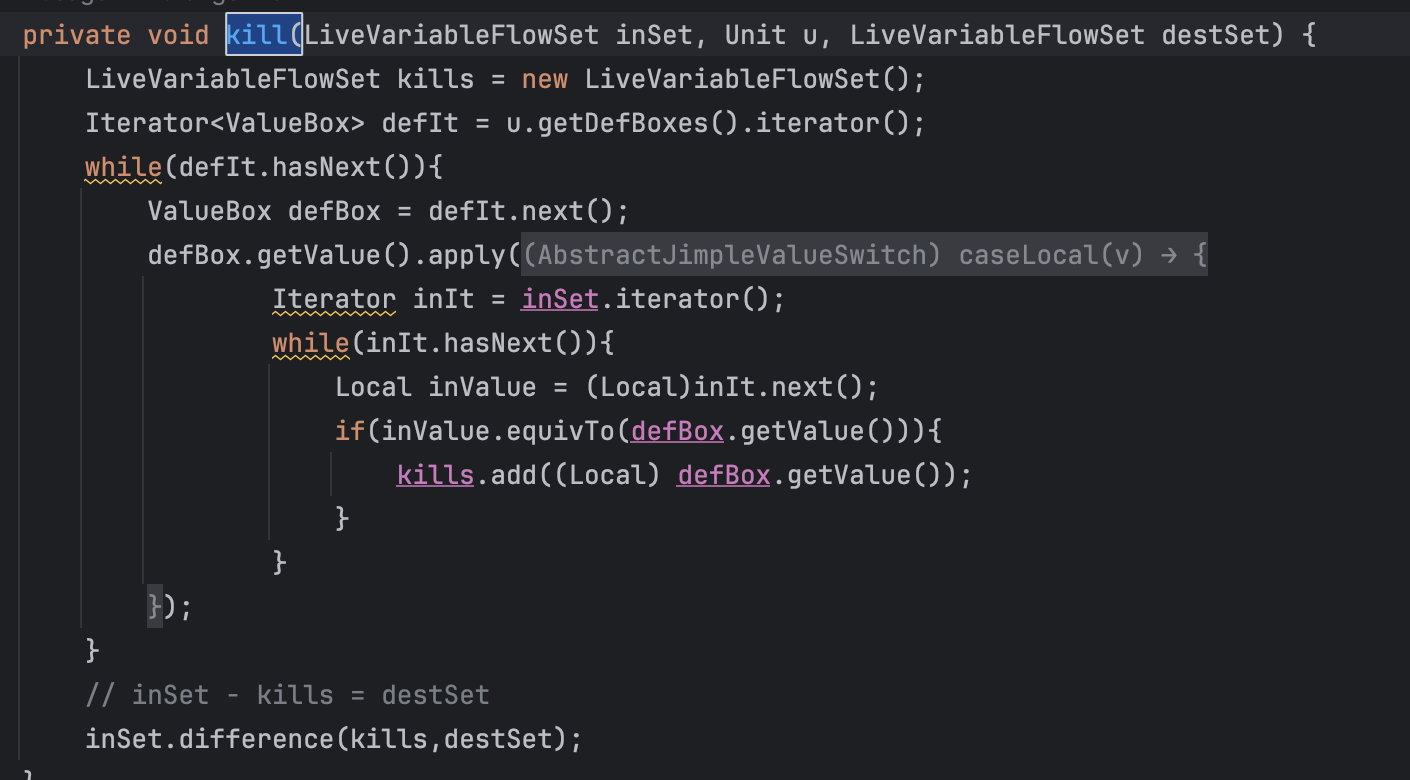
kill方法,重写了caseLocal,意思是在处理局部变量的时候进行的操作。
可以看到defIt是DefBoxes的iterator,DefBoxes指向了所有的定义,然后在caseLocal里,遍历后丢入kills集合。
最后调用inset.difference(kills, destSet), 这个函数的作用就是其上面的注释
destSet = inSet - kills
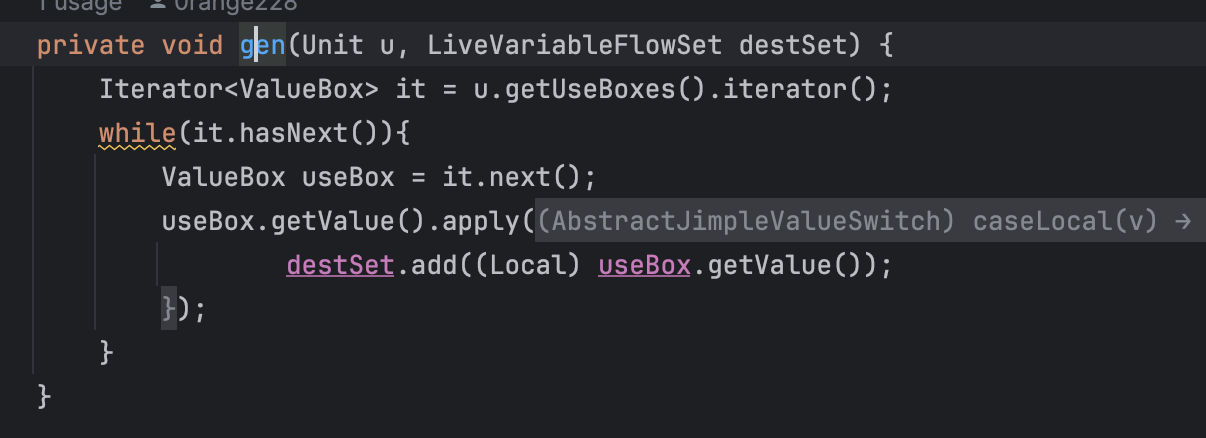
gen方法也差不多,把Use到的变量丢到destSet里。由于这个算法比较简单,都没有重写doAnalysis。
tabby的PollutedVarsPointsToAnalysis
有了简单的例子后,再看tabby的实现就比较轻松了。
1 | |
这里获取了所有的Use和Def,然后对基础类型,局部变量,势利Field和数组四种数据类型进行判断,(基础类型直接跳,不分析),处理好后丢进InitialMap里。
flowThrough:
前面是一些性能相关的,关键代码:
1 | |
可以看到给Unit apply了stmtSwitcher,这个在makeDefault初始化的时候设置为SimpleStmtSwitcher
StmtSwitcher的实现类为SimpleStmtSwitcher,代码中主要处理了InvokeStmt、AssignStmt、IdentityStmt、ReturnStmt四种类型的实现,对应着方法调用、赋值、定义、返回四种类型的jimple语句
SimpleStmtSwitcher
caseAssignStmt
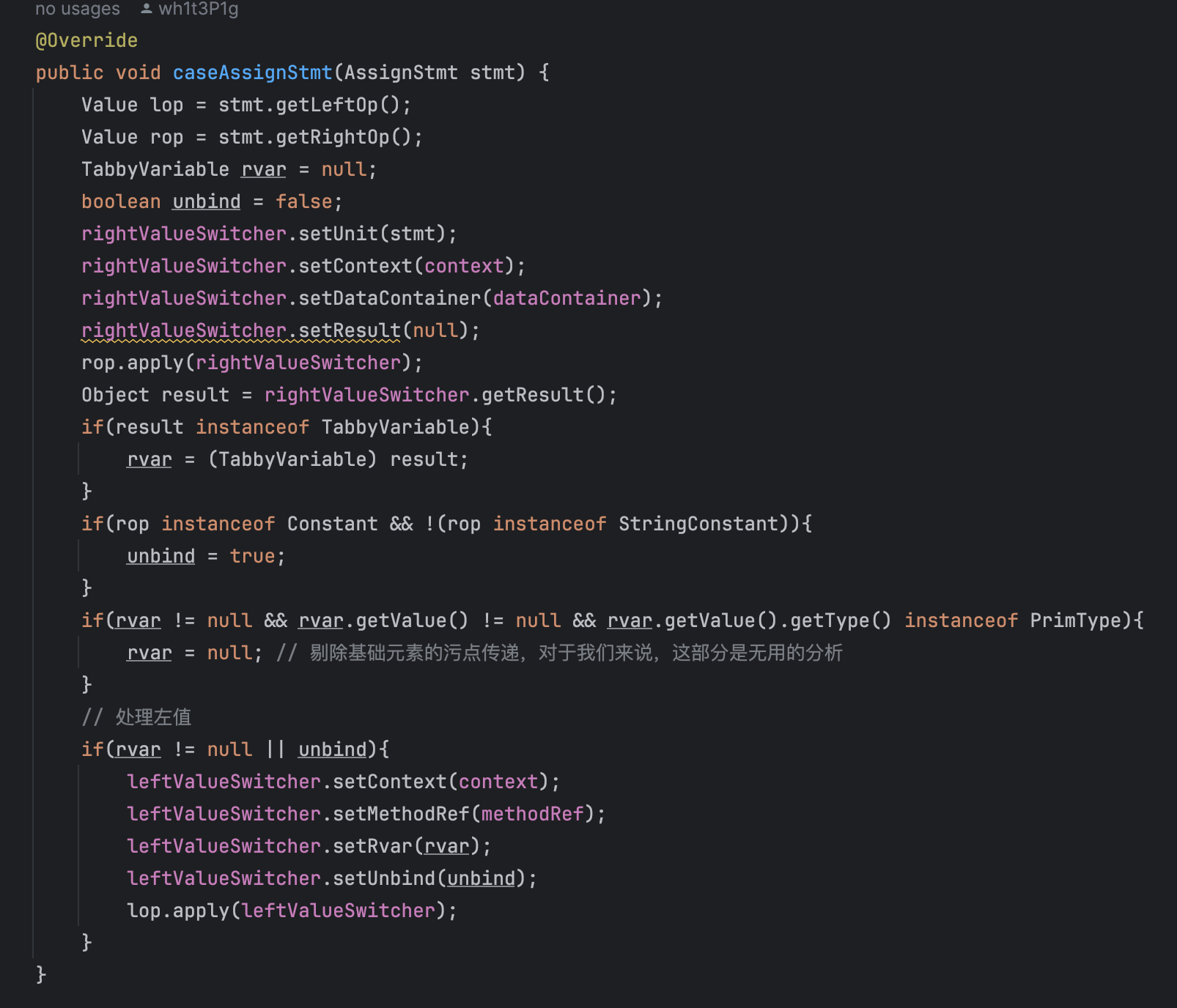
分为左值右值,分别实现了一个valueSwitcher。先看SimpleRightValueSwitcher
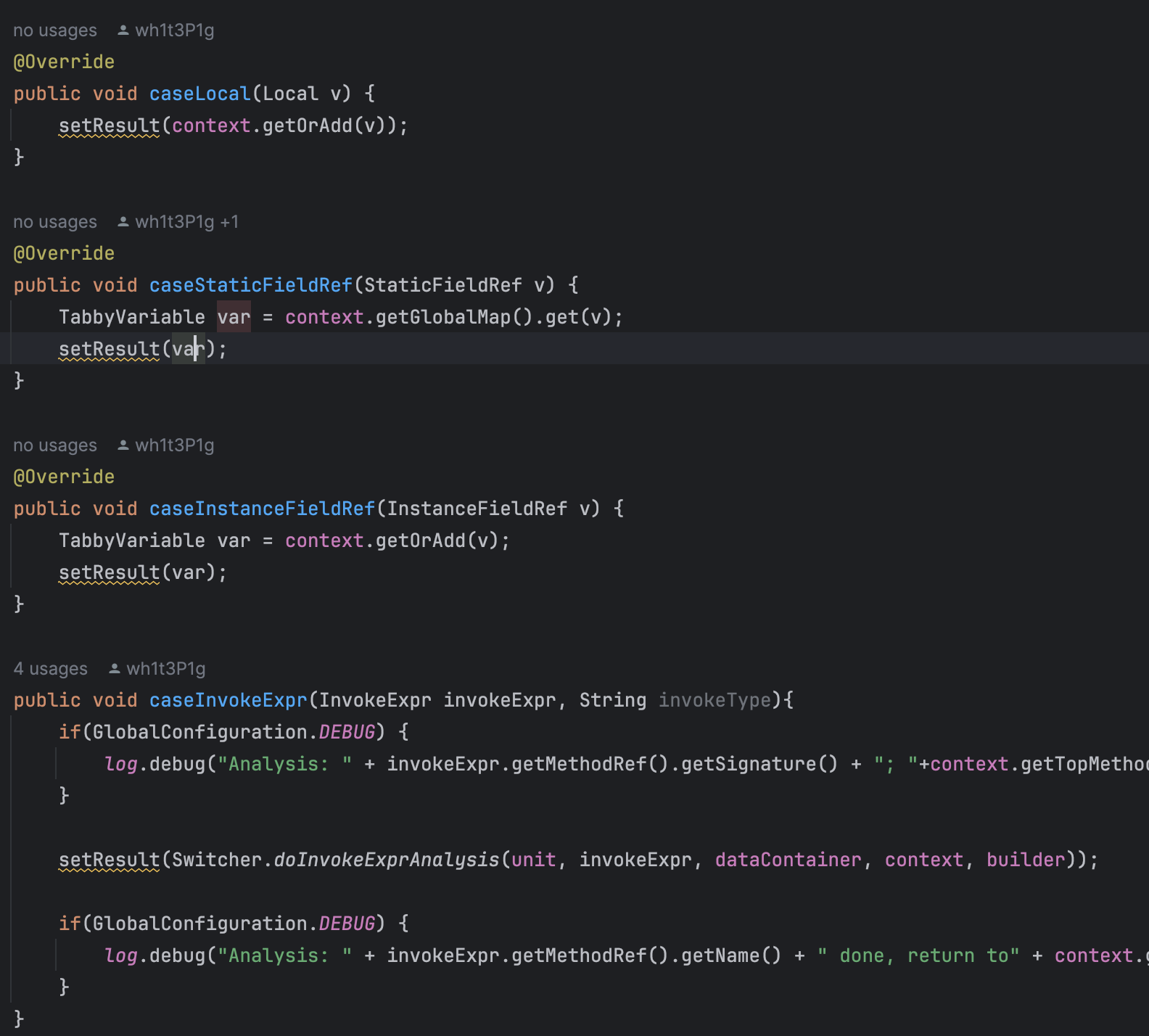
局部变量,static,field和函数的。没啥说的。
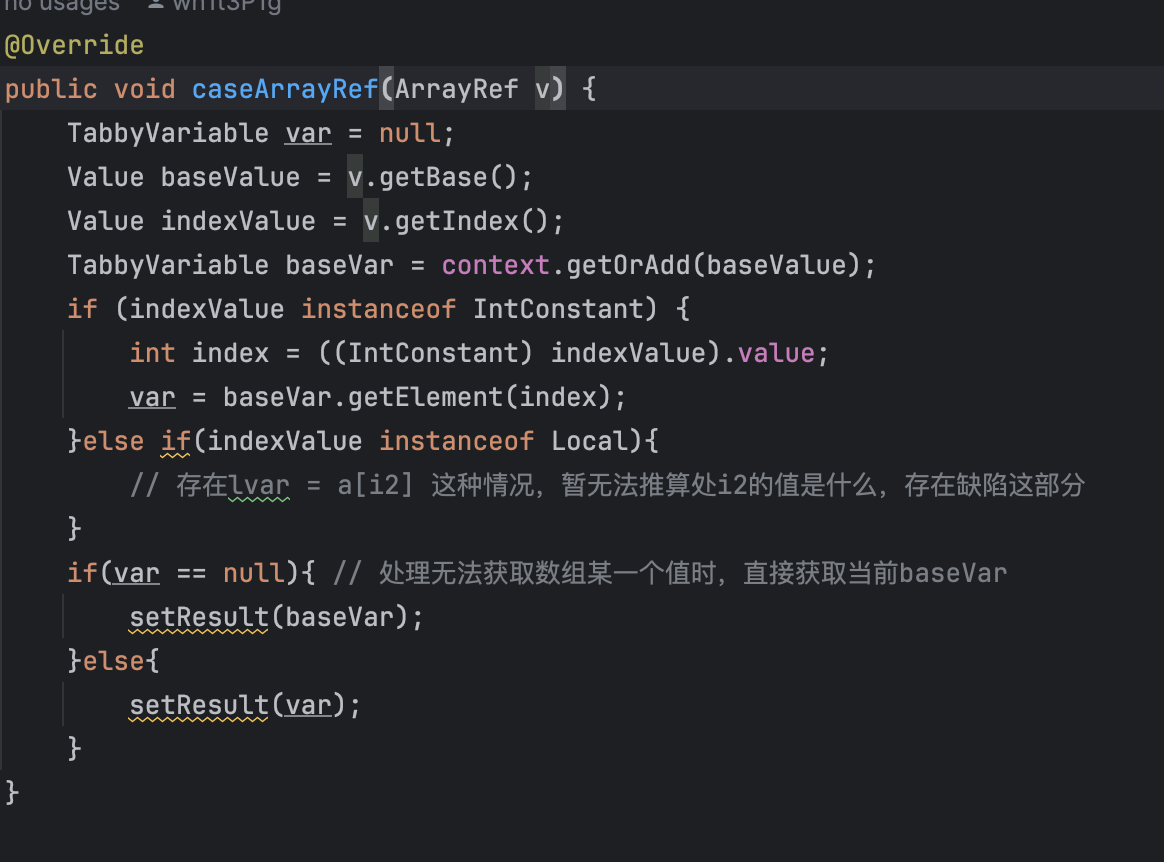
对于Array类型的,通过index获取。但是index是local的情况下没办法推算值,这块功能没实现。所以直接把整个数组setResult了。这样会可能会导致误报增多。
再看Left的,Left这边有点复杂,先从caseLocal看:

这个unbind是caseAssign里的变量,如果右值是CONSTANT或者StringCONSTANT,unbind就为true。很明显这两个类型没法污点传播。
generateAction:
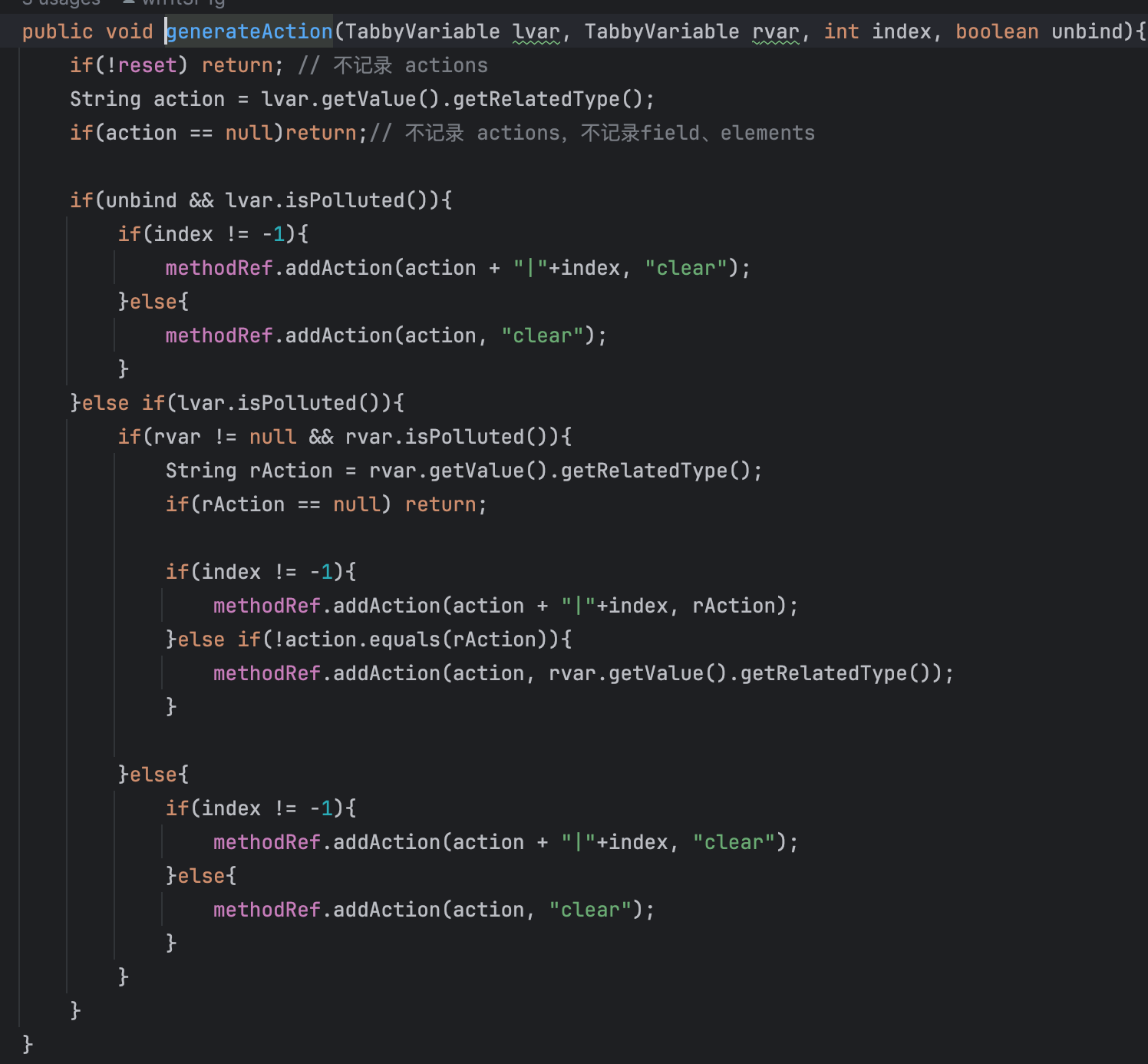
这里就到了action表了,关于这部分的内容见KCON 2022 tabby的ppt,或者https://m0d9.me/2022/10/22/Tabby-%E5%B7%A5%E5%85%B7%E5%88%86%E6%9E%90/
如果右值是被污染的,并且unbind为true。设置action为clear,意思是没用。
如果左值被污染,unbind为false,再判断右值是否被污染,如果右值被污染,正常addaction即可;如果右值没被污染,就设置action为clear
为什么要有第三种情况呢?假如说有这种情况:
a = [EvilInput]
a = b
此时b不是被污染的,a被重新赋值,虽然a是被污染的,但是a也没用了,所以设置action为clear。
然后回到caseLocal,unbind为true, clear左值信息,不是的话把右值赋值给左值。
其他大同小异,不做赘述了。
caseIdentityStmt
1 | |
这部分主要是处理this和param的,因为在Jimple里,这两个会被显式的赋值给局部变量处理,tttang那篇这块写的挺好的:

就不写了。
caseInvokeStmt
1 | |
遇到Object的init直接跳了,减少工作量。
主要逻辑在Switcher.doInvokeExprAnalysis里。

首先是获得pollution,tabby是这样定义的:
-3 不可控
-2 是source(没太理解具体咋起作用的)
-1 是来自当前方法所在类的Field
0-n 是来自当前方法的参数
例如这个例子:

写的挺好的我就不写了。
然后就要继续递归分析调用的这个方法了:
从invokeExpr取出invokeMethod,然后创建一个subContext,递归调用doMethodAnalysis。

m0d9博客提出的问题,因为每次都递归调用到最底层,这个作用就类似于逆拓扑,保证调用时的传播函数可知。
同样的,最后通过spring save到文件里。
完。